One of the most common question templates I receive from prospective clients and clients is: “Can you do some <algorithm> on our data and extract <insights / prediction / analysis>?” Some concrete examples:
- Can you do some NLP on our user comment data to categorize comments into general groups and get sentiment analysis?
- Can you do k-means clustering and find out how many clusters there are?
- Can you do some machine learning and dimension reduction to find out the most important features?
Before I write any code, before I think about loss functions, before I work through math strategy, before I work through product development strategy, before I impute data, before I clean data, before I do EDA (exploratory data analysis), before I write a single query, before I look at a single data record, I follow the barber’s maxim: “measure twice, cut once”.
I engage in a conversation with my client to understand what decisions they are trying to make and why they need to make them.
The questions above and the generic template are a form of the XY communication problem. A well-meaning stakeholder, instead of posing their real question to be addressed, is posing a solution that they believe will address their unexplained problem. In the world of AI / Machine Learning / Data Science / Data Analytics, there is a separation between problem statement, candidate solution methods, solution implementation, and delivery of insights.
Let’s parse this sample, strawman question: “Can you do some NLP on our user comment data to categorize comments into general groups and get sentiment analysis?”
“Can you do some NLP …” starts with a generic methodological / subject area solution. This is followed by an application “… to categorize comments …” with an add-on “… and get sentiment analysis?”. In this framing, the client has not stated what their problem is — their problem is not “categorizing comments” and needing “sentiment analysis”; these are solutions so that they can make some decision / take some action.
My job, first and foremost, is to understand what they actions they want to take and why they want to take them. At an abstract level “what actions to take” are a solution. Why they want to take those actions gets to “what is your action problem”.
Stringing this together, the conversational framework goes like so
- Me: “Why do you want to categorize comments?” [notice that I dropped “NLP”, we’re not there yet].
- Client: “So we have a better understanding of the themes of the comments.”
- Me: “What do you want to do with these themes?”
- Client: “Analyze them.”
- Me: “What do you want to do with the analysis?”
- Client: “Prioritize product development.”
And, aha! We want to prioritize product development. Ok, that’s the actual goal. Continuing further:
- Me: “Are the user comments the only data being used to prioritize product development?”
Here’s where things fork. “Yes, user comments are the only data …” or “No, user comments are one component.”
Let’s pause for a second and see what happens in a Sliding Doors kind of way.
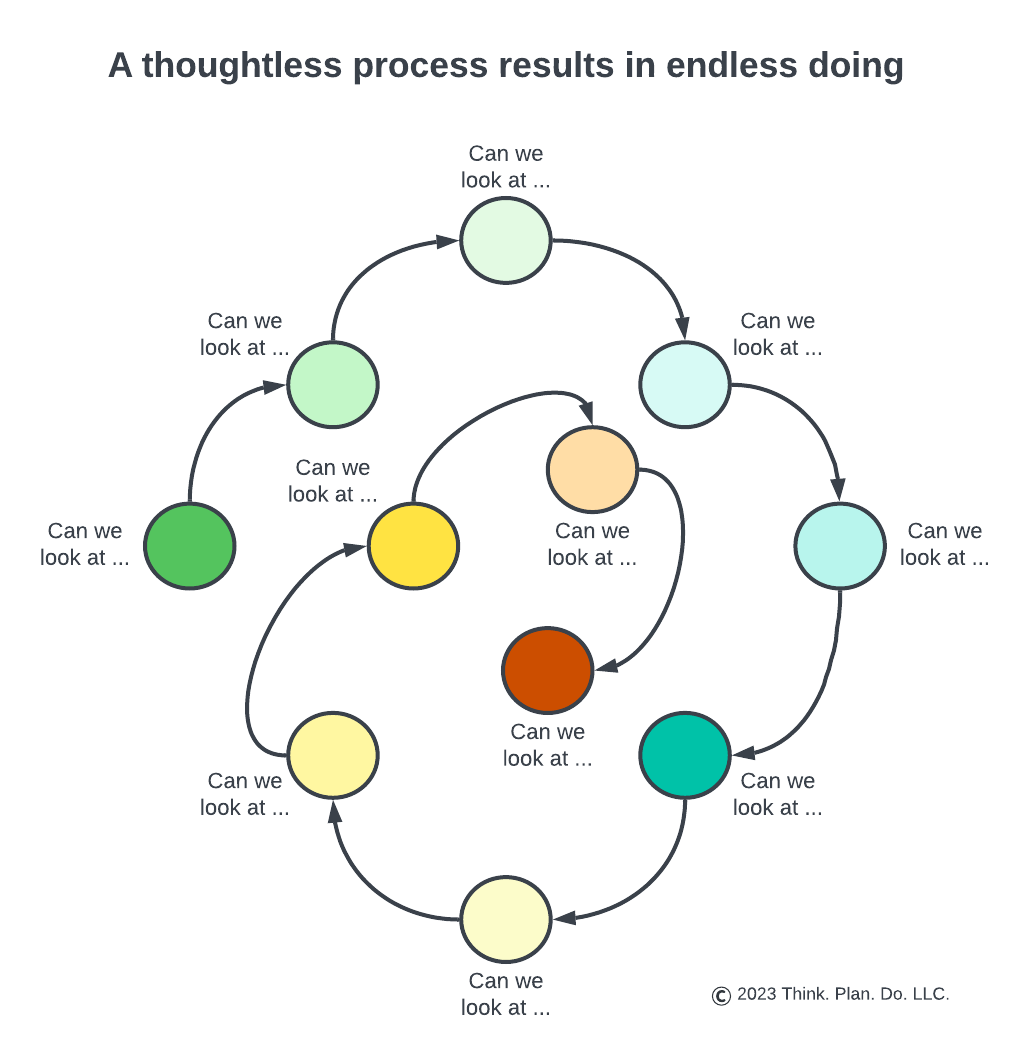
A junior data happy analyst / scientist would have dutifully slaved away “applying NLP”, classified comments, put together an analysis, and delivered a bunch of groupings [rightly or wrongly]. Then the client would review and come back with deeper requests like “can you cohort the themes by user tenure?”. Done. Then a new request: “can you cohort also by product spend?”. Done. Then a new request: “Do these themes correlate with their current product usage?”. Done. Maybe. But the turnaround time gets longer and longer. With more and more cuts and slices, the data continues to thin to the point where if there were any signal it has turned into noise and the original goal of “prioritizing product development” is lost. Nobody is happy. The analyst / scientist has toiled and has been thrashed with the Hansel and Gretel questions and the client’s patience is exhausted as decision deadlines loom.
This reality is the dominant reality in most businesses. Eventually the client does make a decision, but contrary to belief, it was not a data informed decision. Rather it was a “ok, let’s just make a decision, because this one group looks to matter most.”
If we think about why this happens, we can see that this approach gives a sense of motion and “getting things done” and “getting insights”. But it’s a ruse as the (actual unmeasured) failure rate of the approach is high, while, paradoxically, the perceived success rate is high.
On the other hand, an approach that starts with a conversational back and forth will tend to solve actual problems (prioritizing product development) with a higher level of rigor and accuracy at the expense of instant gratification of getting some numbers and at the expense of a perceived challenge to the suggested approach.
How are we going to prioritize product development? Listening to users is certainly one thing to do. But so is an analysis of competitive offerings (and “missings”).
Then there is the case of how user data is sliced. This doesn’t have to be Hansel and Gretel. This can be done upfront. The upfront cost is “thinking”. Jumping straight to doing without a thinking or planning phase ends up being more costly in the long run than a measured, thoughtful approach to analysis.
There is also the upfront requirement to have actual decision thresholds so that it’s not a “game time decision”. I work with my clients to understand what their metric threshold for prioritizing A over B would be. Is it 50% of user comments for a particular feature theme? Or is 10% enough? I also bring the conversation back to business metrics. Is it really “user comment volume?” or is there an interest in tying the analysis to business KPIs?
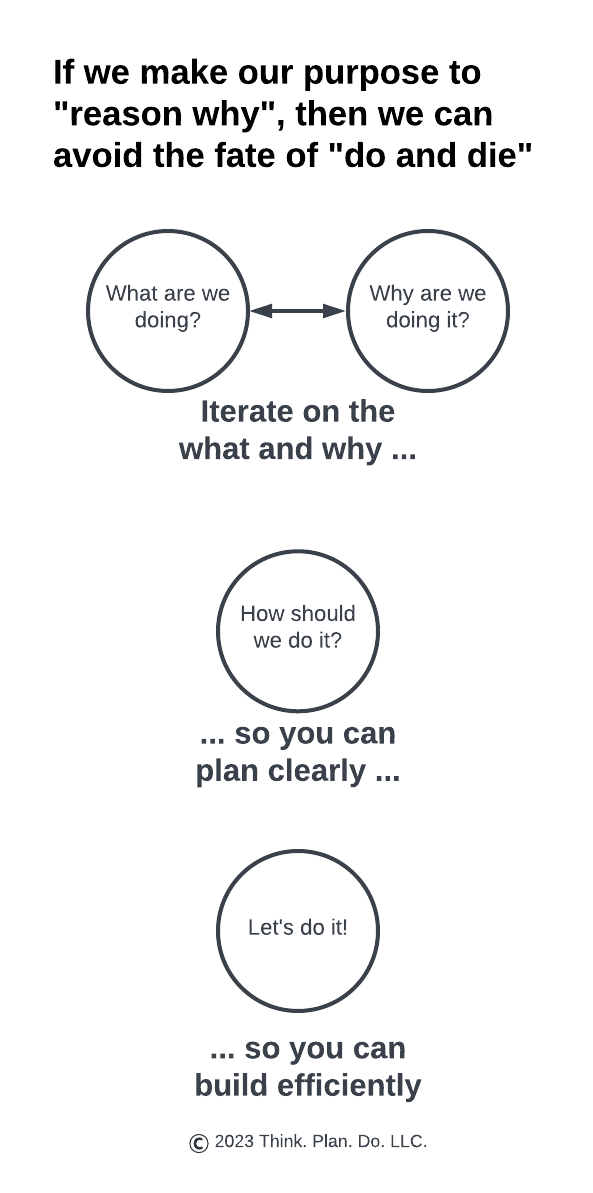
Once we’ve properly boiled down the initial, high level ask to the true ask and found appropriate measurement criteria, then and only then does it make sense to talk about algorithms and data and delivery.
What happens in this “think first, plan second, do last” process is that we don’t waste cycles on wrong doings. Rather we waste cycles on wrong thinking. Correcting for wrong thinking is materially cheaper than correcting for wrong doing. When our thoughts aren’t coherent or well-founded, we feel the dissonance early. We’ll feel it before we get deep in our work because we will be trying to execute on a thought framework that won’t work. The fix for that is to revisit the framework.
When we do without a thought framework, it’s hard to know where and why things went awry. That’s how we spin endlessly with the “now can we look at …” requests.
Revisiting the NLP request, a “think first” approach may very well have us not even go down the route of analyzing user comments with or without NLP. But rather we’ll focus on how we generally think about product development. Perhaps we will arrive at a different set of questions to answer. Perhaps we will find that we need to answer questions like “If we develop X, will we expand our moat?, create a moat?, close the gap between our product and leading industry standards / players?, meet user needs?” where the last question “meet user needs?” can be sourced in a controlled systematic way and not just through the analysis of user comments.