We’re going to continue the Roman numeral theme. For today try out this one, there is only one solution and it’s a multiplication problem! The solution is below the image. This is a good one if you want to use this as an enrichment or warmup exercise (depending on where the student is) if you are teaching a math class.
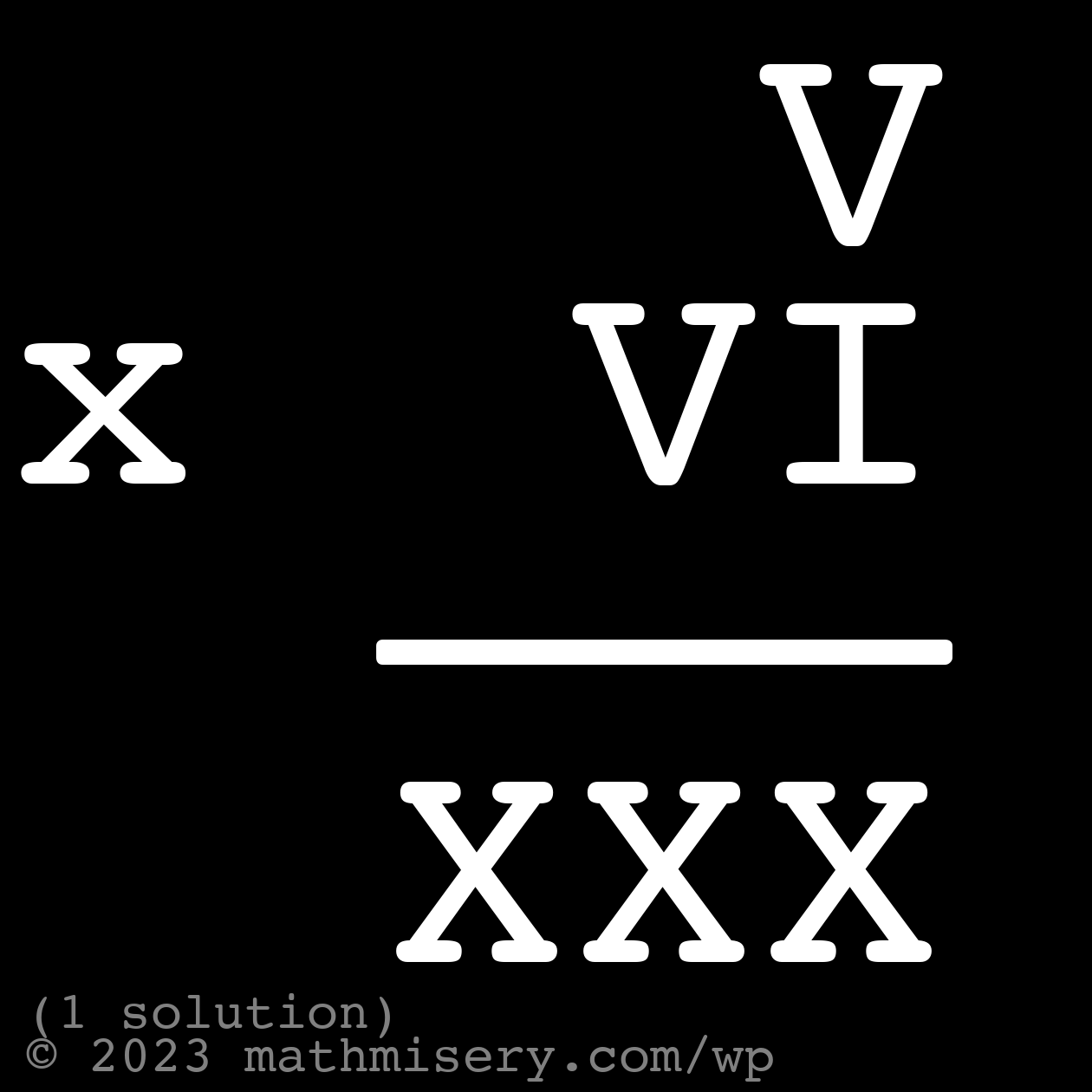
SPOILER SOLUTION!
| V_first | VI_second | XXX_third |
|---|---|---|
| 3 | 37 | 111 |