Let’s say you are a gaming company and you are looking to see if a new feature is going to boost ARPPU (average revenue per paying user). However, you also want to make sure that you’re not going to reduce ARPPU either. The new feature could be a turn off. So before releasing this into the wild to 100% of your users, you decide to run an A/B test on a small cohort.
Without writing all the basics about A/B testing and selecting appropriate cohorts, etc., I’ll assume we’ve done all that correctly. But let it be known that if there is an underlying sampling bias, then worrying about outliers is the least of our concerns. So first, make sure you’ve gotten relevant “apples to apples” comparisons going on. Reach out if you are curious about how to do this [hint: it’s not about getting identical looking groups in A and B, it’s about ensuring that the comparisons are relevant — these are two different things!].
Ok, so let’s say that we’ve allocated 5% of our user base to receive the new game feature and the remaining 95% stays with the current live running app without the new game feature. In the language of A/B testing, the “A” group is the baseline (so our 95%) and the “B” group is the one receiving the “treatment” (new game feature). As we run the test, we are measuring ARPPU and want to see if group B has better ARPPU than group A. For the time being, we’ll also assume that we have enough quantity of samples in both groups. For example, if this is a freemium gaming app, for example, and the B group has 100 users, it’s entirely possible that there could be zero paying users, in which case ARPPU doesn’t make sense. That doesn’t necessarily mean that the feature is bad. It could simply mean that we don’t have enough data.
And this finally brings me to the case of outliers. An outlier, by definition, is a data point that is considered extreme relative to other observed data points. In gaming apps and other products that have business models where users can spend from $0 to possibly millions, the existence of low frequency high impact events have a distortive effect on statistical tests, especially those involving means. So if we want to understand our outliers, we have to have enough data to get a sense of what extreme is. For example, if in my B group, and absence of any other knowledge, I observe two paying users, one with total purchase of $5 and another of $1000, which value is the outlier? At this point, we may be tempted to consult our previous knowledge [older data] our the A group to see what “normal” purchasing behavior looks like. All of this is good and well if we want to get a sense of the landscape, but there are a few problems and questions.
Let’s say that we somehow conclude that the $1000 purchase is truly an outlier in the sense that it’s not a data error, but rather a valid data point that is extreme. We might be tempted to look into our “what do we do with outliers” toolbox and come up with a few options. These could be (not exhaustive and in no particular order):
- Winsorize
- Throw the data point out
- Apply some non-uniform weighting scheme
- Only look at the interior 80% of the data
- Consider redefining our performance metric (eg, instead of ARPPU, we might want MRPPU (median revenue per paying user)) to mitigate the impact of extreme values
- Generate synthetic data from a (believable) prior distribution
The first problem with any of the above is that our B group has, literally, two data points of success. So modifying those via Winsorizing, tossing the data out, or deciding on a weight scheme will, in effect, be modifying 50% of our data. This is generally not a good way to go. Looking at the interior 80% is senseless since we only have two data points. Redefining the performance metric could work, but again, the underlying variance is so high that almost any statistical test will be inconclusive / meaningless (Also, since in this particular case we only two data points, median and mean are the same thing.). And good luck on getting anyone to accept “fake” data in an A/B test, though that could be an option if we sold it the right way to stakeholders (think probability that group B is outperforming group A while the test is running … but again these are treacherous waters).
So, in this particular case where we have too few data points, we really can’t do much other than stick our finger in the wind and come up with some estimate for the likelihood / probability that group B is outperforming group A under whatever performance metric we have decided to go with.
Now, what if we were in a better world where we had ample data points of success in group B — say 1000 data points, where the largest purchasing user spent $1000? And between groups A and B, all other users had a maximum purchase of say $30? Clearly the $1000 is an outlier. So what should we do about it? Similarly, would the way we handle an outlier in group B be different from how we handle an outlier in group A? If so, why? If not, why not?
What often happens in scenarios like this one, where we do have enough data in both our test and control groups and when one or both groups have extreme data points present, is that we tend to want to “prettify” the data so that we are looking at “typical” data which then allows us to utilize standard statistical tests. The general rationale for this is that summary statistics, especially mean and standard deviation, do not reflect the distribution of the majority of the data. Extreme values pull the mean further away from the center of the data. Additionally, the standard deviation can be larger than the mean itself and this poses boundary problems (ARPPU can’t be negative, eg), which in turn means that assumptions about normality of data can be tenuous since we likely won’t be in convergence territory.
Nevertheless, bootstrap resampling methods can allow us to produce enough results so that we can estimate probabilities that group A outperforms group B. We can also measure the outlier effect by deleting from or Winsorizing the point (or points) the data set and rerunning our bootstrap analysis to see if the outlier(s) was (were) the singular factor. We could also swap outliers between the two sets and see if that changes the verdict.
Here’s an example of comparing bootstrapped means between the test and control. The points in blue indicate that the test had a higher mean than the control and vice versa for red. We might be tempted to conclude that the test group outperforms the control. And no one would really fault us for doing so.
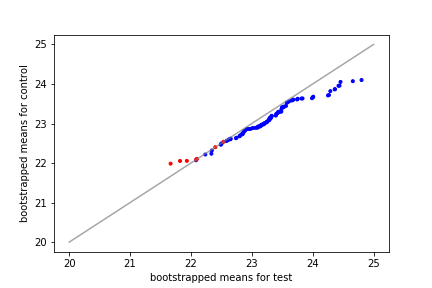
Test vs Control bootstrapped means; fake data for illustrative purposes
And again, this is all good and well and likely sound statistical methodology.
But …
Are we thinking about the product or are we thinking about statistics?
Before we go down any of these statistical routes to determine if group A is outperforming group B, we have to ask ourselves one basic question that I think no one asks.
Did our test induce the outlier?
In other words, how sure are we that the new feature we are promoting didn’t actually create the outlier? This is a difficult question to answer since it is highly unlikely that we can get into the head of users and know with certainty that it was our product design that induced the spend and not just a case that our “whale” happened to fall in the test group rather than the control group.
If we genuinely believe that the outlier was caused by our feature, then we shouldn’t muck with the data! Rather, we should call out our assumption explicitly. On the other hand, if we believe that the outlier was a whale that got dropped into the test group randomly and would have spent just as much in the control, then we have statistical methods for dealing with this [eg, swapping or moving the outlier to the control group and running tests to see if our verdict changes and by how much].
But the main point here in all of this is before we jump to “dealing with outliers” from a statistical and data analysis standpoint, we really have to think about the product usage and causality first. Did the test create the outlier?