Text, audio, video. There are AI tools for working in all of these media either individually or in concert. And we have seen the level of sophistication grow at a rate faster than what we had imagined.
Ok, now consider this version of the above paragraph:
The advancement of AI technology has enabled us to work with text, audio, and video in a seamless manner, either separately or combined. The growth in sophistication of these tools has surpassed our initial expectations, advancing at a rapid pace.
Which was written by a human? And which was AI generated? Or were they both generated by AI or both by a human? Any answer can seem plausible. Before we find out who authored what, let’s consider what is happening with AI content generation.
There are algorithms, ethics, data, training philosophies, tradeoffs between getting it right and getting it out, and more when it comes to building any data-based product. Leaving the abstract world for a moment and focusing on the nuts and bolts of building AI products, at their heart is “data” first and “algorithms” second. Eventually, data and algorithms enter into a feedback system where after a few maturation cycles, it won’t be clear clear which is the chicken and which is the egg.
This poses a bit of a quandary for feedback driven systems (not just AI / data science products, but product development in general). For AI content generation products in open systems which are trained on human generated content first to generate an initial product that is then used by humans to create more product which is then fed back to the AI machine, who is training whom?
Will we eventually produce content more like the AI? And when the AI trains on that new swath of content, will it just reinforce its own writing algorithms? What would it mean for us to “better” our content?
What happens when we try to compare human submissions versus AI submissions and we can’t tell the difference? Will we say that we have successfully trained the AI? Or is it that AI has successfully trained us?
Are we thinking or are our correlative biases being exploited?
Consider this “Smart Compose” suggestion.

Did I want to write “thoughts” or did I want to write “termites”?
And why not suggest the profane in the example below?

How much of our content, in this case writing, comes from our own thoughts and how much is simply suggested to us at a pace that’s fast enough that it bypasses our thoughts and leads us into benign, but coerced, agreement to a message that we may not have wanted to write in the first place?
We’ve agreed to spellcheck, grammar check, and even autocorrect for those pesky “teh” typos. But we also have “Smart Compose” (Google, for example, but other email systems have this as well) that is personalized.
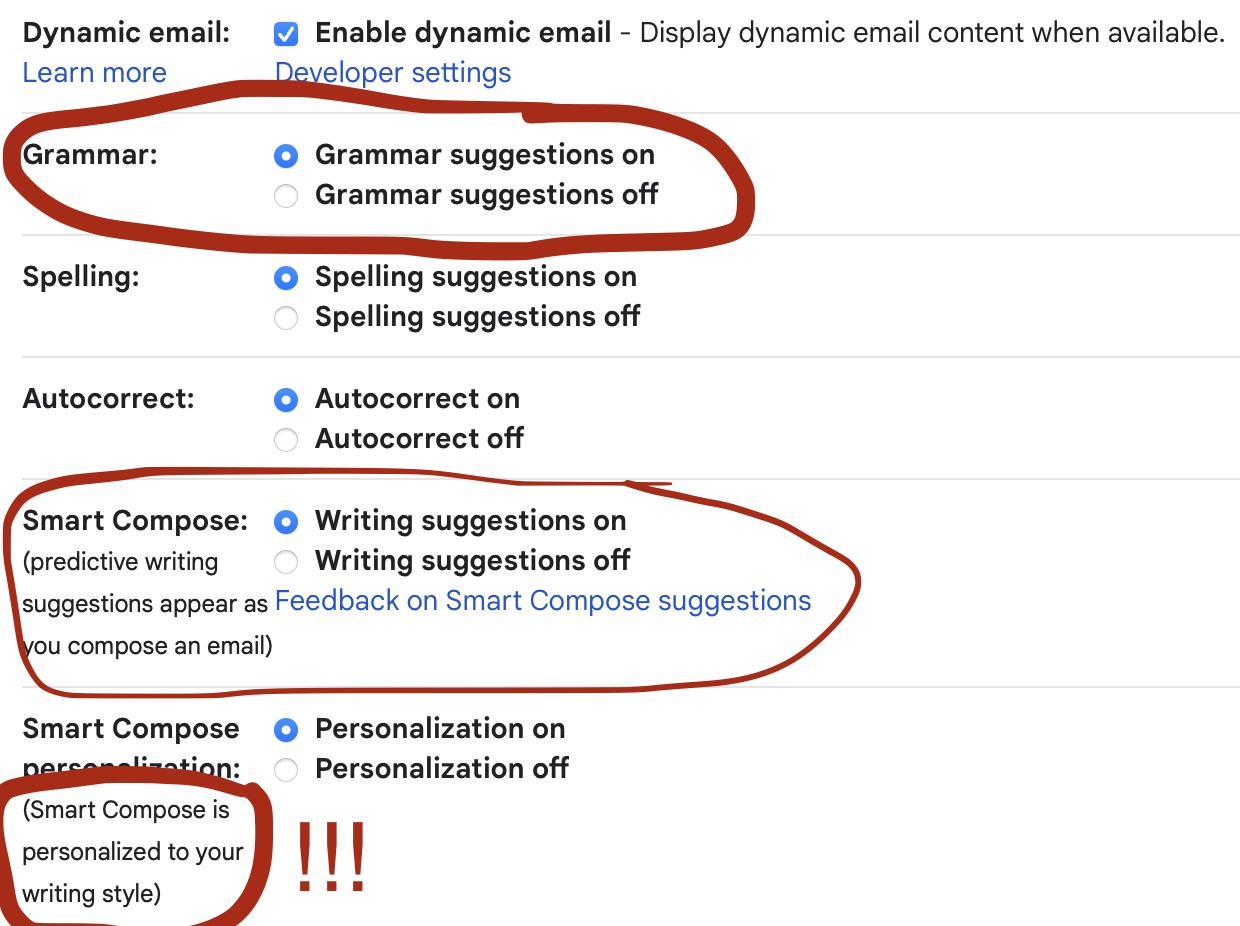
What does “personalization” actually mean? Can I use the word “actually” if the AI grammar police are going to tell me to remove “actually” so that my writing can be more concise? Actually, I’ll use “actually” whenever I damn well please.
Is AI helping us to produce better content? Or is content being done on us?
This will come down to how much we understand and accept correlation for intelligence. The domain of invention is human. Once we cede that we will become biological automatons no different than the ants that go marching along to pheromone trails. Caveat emptor.
And if you want to know who wrote which paragraph at the top, here you go. You decide which is “better”.
